
One of our Cubeo AI users built an agent to extract data from legal documents.
Their agent would search through PDFs (hundreds of pages each) looking for specific clauses. Just a few rows of data.
The agent worked. But their token costs were insane.
They were processing hundreds of thousands of tokens per task. Just to find a few lines in a 300-page contract.
We looked at their setup. The prompts were good. The model was fine.
The problem? The amount of data the Agent had to process.
Let us explain the difference.
The Misconception That's Costing You Money
Most non-tech people think: Prompt = Context
They think the words they write are everything the AI sees.
Wrong.
Your prompt is one piece. Context is everything.
The Desk Analogy
Think of your AI’s context window as a desk.
Your prompt? That’s one sticky note on that desk.
Everything else on the desk:
- The chat history from 10 messages ago
- Three PDFs you uploaded
- Results from five different tool calls
- A web search with 50 snippets
- Memory from yesterday’s conversation
Now ask yourself: How good does that one sticky note need to be if the desk is covered in junk?
It doesn’t matter how clear your prompt is. The AI is distracted by everything else.
This is why focusing only on prompts fails.
What Context Actually Includes
Context isn’t just your instructions.
Context is everything the AI sees:
Your Prompt: “Extract the liability clause”
Plus:
- Available tools (Search PDF, Web Browser, etc.)
- Tool results (every search, every page read, every API response)
- Memory (what it tried, what worked, what failed)
- Documents (PDFs, web pages, files)
- Chat history (everything said so far)
All of this costs tokens. All of this affects the output.
Your prompt is just one piece.
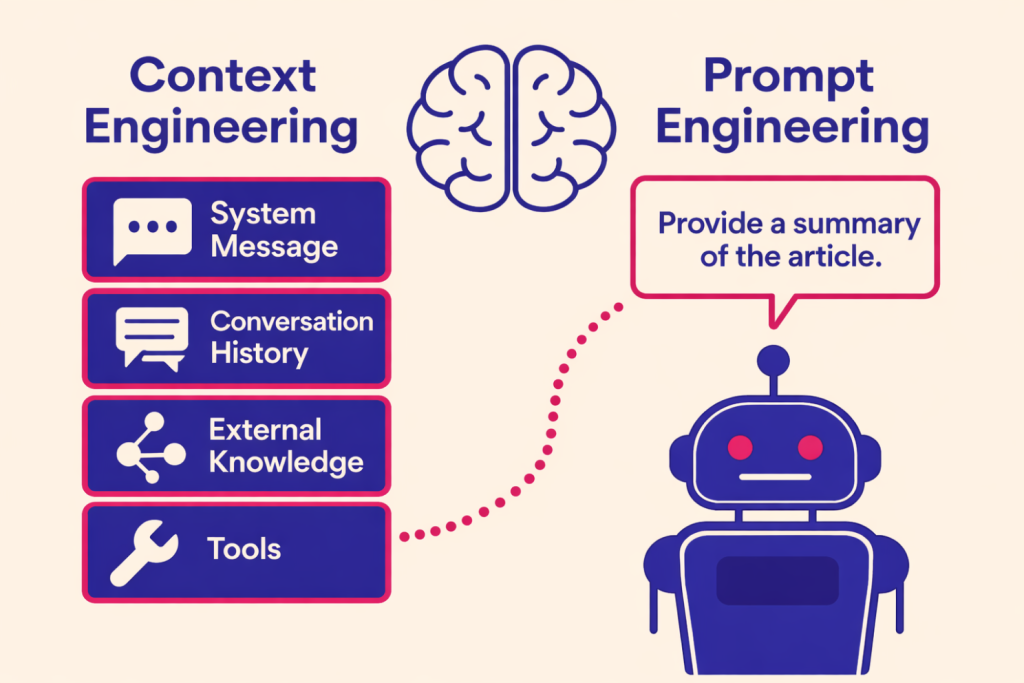
Prompt Engineering vs. Context Engineering
Prompt Engineering = What you tell the AI to do
- Clear instructions
- Good examples
- Step-by-step thinking
- Right tone and format
- Chain-of-thoughts
Context Engineering = What you let the AI see
- Which tools can access what data
- How much data tools return
- What stays in memory vs. gets discarded
- How information is structured
- What limits you set
Most people only do prompt engineering then wonder why their costs explode.
Because bad context makes perfect prompts useless.
A Real Example: PDF Agent Extractor
Back to that legal document agent.
Before (Only Prompt Engineering):
Prompt: “Find the liability clause in this contract and extract the key terms.”
What happened:
- Agent opened 300-page PDF
- Extracted ALL text -> 180,000 tokens into context
- Searched through everything
- Found clause on page 247
- Extracted data
Cost: ~$2.50 per document, Time: 2-3 minutes, Tokens: 200,000+
Perfect prompt. Terrible context.
After (Context Engineering):
We didn’t change the prompt.
We changed the context:
- Limited tool output to 5,000 tokens max
- Agent searches PDFs -> gets list of relevant documents
- Agent wants to see the PDF X
- Its content exceeds 5,000 tokens -> we save the full pdf content into a text file (using computer access)
- Agent searches into the file with simple linux commands
- Only loads relevant sections into context
- Extracts data
Cost: ~$0.25 per document, Time: 30 seconds, Tokens: 20,000
90% reduction. Same task. Same prompt.
We just controlled what entered the context.
Why This Actually Matters
You can’t control what a non-deterministic agent will explore.
You tell it: “Research this company”
You can’t control:
- Which search results it clicks
- How deep it reads each page
- What tangents it follows
- How much it loads into context
That’s what makes agents powerful. They explore.
But if you only engineer the prompt? They’ll explore inefficiently.
Your job isn’t to write prompts that prevent exploration.
Your job is to design the environment where exploration stays lean.
That’s the difference between prompt and context engineering.
A Quick Comparison
Task: “Find and verify the CFO’s email for Company X”
Agent A (Prompt-Only Focus):
- Prompt: “You are an expert. Be thorough. Use all the tools.”
- Web search -> 50 results loaded into context
- Clicks 15 pages -> Full HTML in context
- Makes 40+ tool calls
- Cost: $1.20 | Time: 3 min | Success: 75%
Agent B (Context-Engineered):
- Same prompt
- Search limited to 10 results max
- HTML parser returns only text
- Results saved to file
- Agent searches into the file, not full pages
- Makes 8 tool calls
- Cost: $0.15 | Time: 45 sec | Success: 95%
8x cheaper. 4x faster. More accurate.
Same prompt. Different context strategy.
Common Mistakes
“Bigger context windows solve this”
No. Bigger windows just fit more garbage. The AI still gets confused.
“RAG fixes context problems”
Only if done right. Retrieving 50 documents is still too much. You need 3-5 highly relevant ones.
“Better prompts will fix it”
Your prompt can’t stop an agent from loading a 500-page PDF. That’s a tool design problem, not a prompt problem.
“More tools = better agent”
More tools = more ways to pollute context. You need better tool design, not more tools.
The Core Insight
Non-deterministic systems need deterministic constraints.
You give agents freedom to explore.
But you must architect the environment they explore in.
At Cubeo AI , we watch users build agents every day.
Professionals? They design contexts. They understand that AI Agent development is a trial & error approach.
Beginners? They write perfect prompts and wonder why costs are insane and why their AI Agent is not doing what they expect it to do.
The difference is simple:
Prompts tell agents what to do. Context engineering makes sure they do it efficiently.
Both matter.
But if you ignore context? Your agent works. It just costs 10x more.
And when you’re running thousands of tasks per day? That 10x becomes real money.
Takeaway
Stop thinking: Prompt = Context
Start thinking:
- Prompt = The sticky note (your instructions)
- Context = The entire desk (everything the AI sees)
Clean the desk. Limit the tools. Structure the data.
Then your prompts will actually work.


